1. 왜 이 글을 쓰게 되었나요?
2. 성능 테스트
3. 샘플 데이터 정보
1. 왜 이 글을 쓰게 되었나요?
쿼리 튜닝을 위해 인덱스를 생성하는 일은 개발하면서 자주 접하게 됩니다.
그런데 최근 증분 데이터를 다른 시스템(Redshift 등)으로 옮길 때도 인덱스를 활용할 수 있다는 사실을 알게 되었습니다.
그리고 우리가 평소에 사용하던 인덱스는 어떤 역할을 하는지 궁금해졌고,
정리하는 마음으로 이 글을 작성하게 되었습니다.
BTREE (Balanced Tree) 인덱스
Postgres의 기본 인덱스 타입입니다.
CREATE INDEX idx_parcel_tracking_customer_name ON parcel_tracking (customer_name);
요 쿼리를 수행 했을 때 생성되는 인덱스입니다.
값을 정렬된 트리 구조로 관리하여 범위 검색, =, <, >, <=, >=, between, in 등의 연산에 효율적입니다.
수십 GB 단위 이하의 테이블 적합한 인덱스 생성 방식입니다.
인덱스 생성 시 많은 용량을 차지합니다. 즉 인덱스 생성 시간이 오래 걸립니다.
데이터가 자주 업데이트/삭제될 경우 리밸런싱 비용이 발생하게 됩니다.
BRIN (Block Range INdexes) 인덱스
대용량 테이블에서 사용하도록 고안된 저비용 인덱스입니다.
때문에 인덱스 생성 시간이 빠르고 적은 용량을 차지합니다.
값 자체가 아니라, 테이블의 페이지 블록 단위로 최솟값/최댓값 메타데이터만 저장합니다.
검색 시, 조건에 해당하는 블록만 읽게 하여 I/O 비용을 절감합니다.
CREATE INDEX idx_parcel_tracking_created_at ON orders USING brin (created_at);
테이블이 수억 건 이상이고
해당 컬럼이 물리적 순서에 따라 값이 대략적으로 정렬되어 있는 경우 (예: 날짜, 증가하는 ID)
조회 빈도가 적고, 주로 Full Scan으로 처리되는 대형 테이블 최적화 용으로 사용합니다.
2. 성능 테스트
대상 데이터: 10,000,000 rows (약 2.8GB)
BTREE (Balanced Tree) 인덱스
인덱스 생성 전

인덱스 생성 시간 (tracking_number에 index 생성)

인덱스 사이즈

인덱스 생성 후

BRIN (Block Range INdexes) 인덱스
인덱스 생성 전
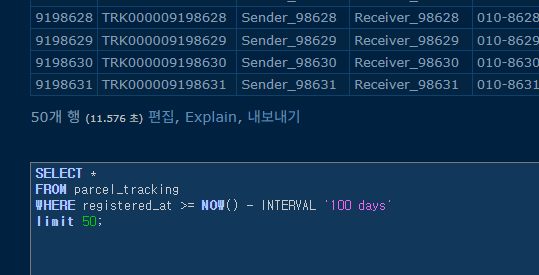
인덱스 생성 시간

인덱스 사이즈
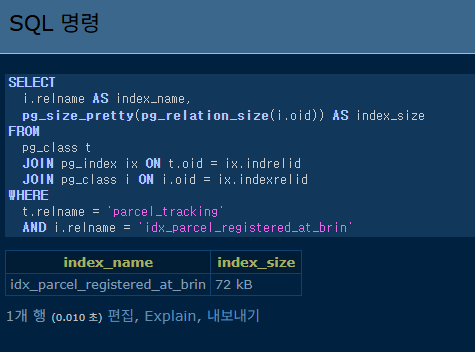
인덱스 생성 후

| 구분 | BTREE | BRIN |
| 주 용도 | 소~중형 테이블, 빠른 검색 | 대형 테이블, Full Scan 최적화 |
| 지원 연산 | =, <, >, <=, >=, BETWEEN | =, <, >, <=, >=, BETWEEN |
| 데이터 분포 | 다양해도 괜찮음 | 값이 물리적으로 정렬된 경우 유리 |
| 인덱스 크기 | 큼 | 작음 |
| 유지 비용 | 큼 | 적음 |
| 성능 | 높은 정확도와 빠른 속도 | Full Scan 대비 효율 개선 (정확도 낮음) |
3. 샘플 데이터 정보
Table 정보
CREATE TABLE parcel_tracking (
id BIGSERIAL PRIMARY KEY,
tracking_number VARCHAR(20) NOT NULL,
sender_name VARCHAR(50),
receiver_name VARCHAR(50),
sender_phone VARCHAR(20),
receiver_phone VARCHAR(20),
origin_address TEXT,
destination_address TEXT,
delivery_status VARCHAR(20),
registered_at TIMESTAMP,
delivered_at TIMESTAMP
);Dummy 데이터 정보
INSERT INTO parcel_tracking (
tracking_number, sender_name, receiver_name,
sender_phone, receiver_phone,
origin_address, destination_address,
delivery_status, registered_at, delivered_at
)
SELECT
'TRK' || lpad(seq::text, 12, '0') AS tracking_number,
'Sender_' || (seq % 100000),
'Receiver_' || (seq % 100000),
'010-' || lpad((seq % 10000)::text, 4, '0') || '-' || lpad((seq % 10000)::text, 4, '0'),
'010-' || lpad(((seq + 1) % 10000)::text, 4, '0') || '-' || lpad(((seq + 1) % 10000)::text, 4, '0'),
'Seoul Gangnam ' || (seq % 100),
'Busan Haeundae ' || (seq % 100),
CASE WHEN seq % 5 = 0 THEN 'DELIVERED'
WHEN seq % 5 = 1 THEN 'IN_TRANSIT'
WHEN seq % 5 = 2 THEN 'OUT_FOR_DELIVERY'
WHEN seq % 5 = 3 THEN 'RETURNED'
ELSE 'REGISTERED'
END,
NOW() - (seq % 1000 || ' days')::interval,
CASE WHEN seq % 5 = 0 THEN NOW() - (seq % 500 || ' days')::interval
ELSE NULL
END
FROM generate_series(1, 10000000) AS seq;
끝~
'DB' 카테고리의 다른 글
| SpringBoot redis 활용(.haskey, .set, .get) (0) | 2021.10.22 |
|---|